软件开发因AI有了根本性转变?
刚刚,带火“Vibe Coding”风潮的前 OpenAI 大佬 Andrej Karpathy,在 YC 的演讲刷屏出圈!
这是一场足以改变你对编程、对大模型、对未来软件形态理解的深度分享。
Karpathy 一开场就掷地有声地说:
“软件正在再次发生根本性的变化。”
这句话引爆了 Hacker News 社区热议——哪怕最初发布的只是一份错漏百出的转录稿,依旧挡不住大家的疯狂转发与评论。
而在 X 上,YC 创始人 Jared 表示:
“这场演讲发人深省,让人对 LLM 有了全新的认识。”
Karpathy 的核心观点是:
过去 70 年,软件的底层范式几乎未变;
但短短几年内,软件连续发生了两次结构性巨变;
AI 正把“写代码”这件事,变成“写提示”、“对话”、“控制 Agent”;
英语,正在成为新的“编程语言”。
他说:
“我们正站在一场软件重写的浪潮上,我们有大量的工作要做、大量的软件要写,甚至重写,这将远超我们想象。”
现在,这场官录视频终于新鲜出炉!
我们为你提炼了这场演讲的干货,图文并茂,帮你还原Karpathy大神眼中的软件3.0,从中读出软件未来的走向、LLM 背后的操作系统哲学、以及“AI赋能人类”的正确姿势。
📺 视频地址:
https://www.youtube.com/watch?v=LCEmiRjPEtQ
话不多说,准备迎接 Software 3.0 的世界!
世界!
01
“软件地图”:Software 1.0 → 2.0 → 3.0
我们可以先看看“软件世界”的整体形态。假设我们有一张“软件地图”,那这张图展示的是 GitHub 上的全部项目。
这些项目可以看作是人类写给计算机的“指令”,告诉它如何在数字世界中执行任务。
你放大地图,可以看到各种各样的代码仓库——这些就是我们已经写好的所有代码。这些代码是“指令”,告诉计算机怎么在数字世界中完成任务。
我几年前观察到,软件开始向一种新形式演化,我当时给它取名叫 Software 2.0。
所谓 Software 1.0,是传统意义上我们手写的代码;
而 Software 2.0,指的是神经网络,准确地说是它们的参数(weights)。我们不再直接写“代码”,而是调数据、跑优化器,生成参数。
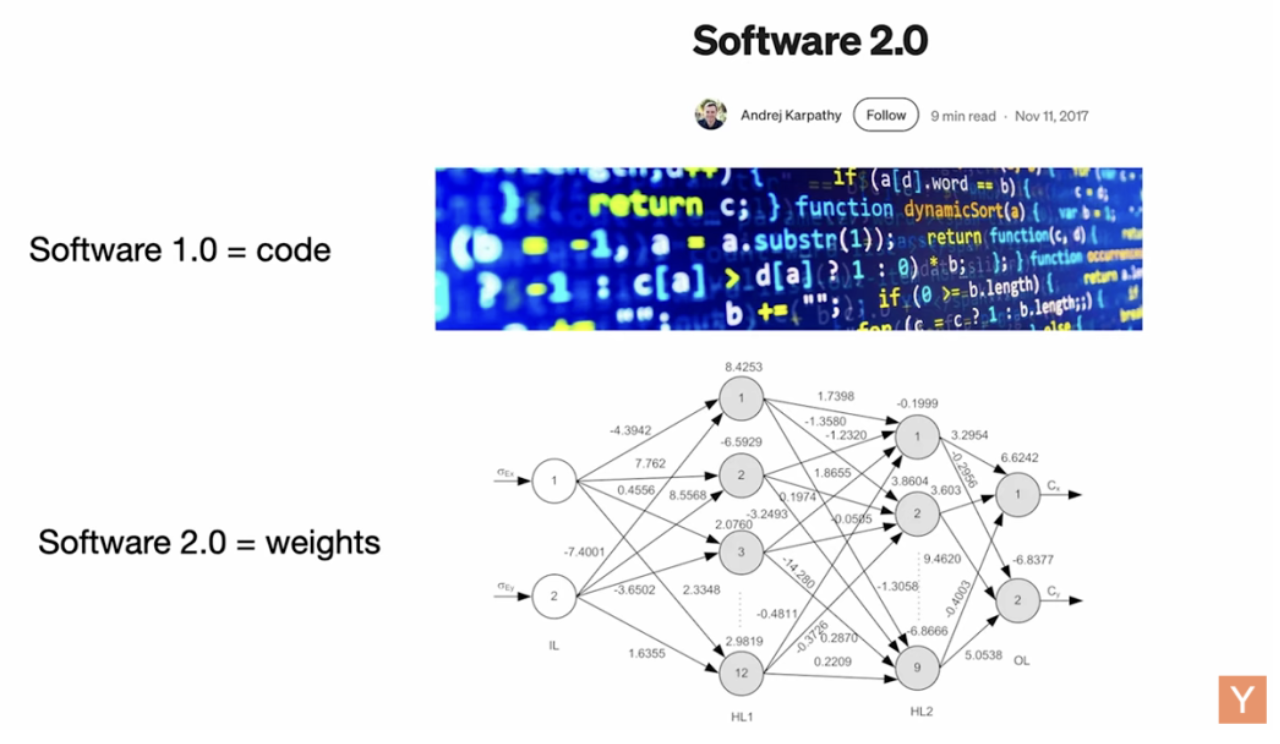
当时的神经网络还只是被看作一种分类器——就像决策树一类的工具。因此“训练神经网络”的流程,倒还挺自然。
如今,我们在 Software 2.0 世界中也有了类似 GitHub 的东西——比如
Hugging Face、模型地图等,它们就像代码库一样存储着不同的模型。
你看到的中间那个大圆圈,其实是 Flux(一个图像生成模型)的参数。每次有人在 Flux 上微调模型,就像是对 GitHub 的一次提交。

一直以来,我们所熟悉的神经网络,其实都更像“功能固定的机器”——比如图像分类器。
而这一次,我认为最根本的改变是:
神经网络开始“可编程”了。
这就是我们所说的大语言模型(LLMs)。
在我看来,这是一种全新的计算机。我甚至认为它值得被称为Software 3.0。
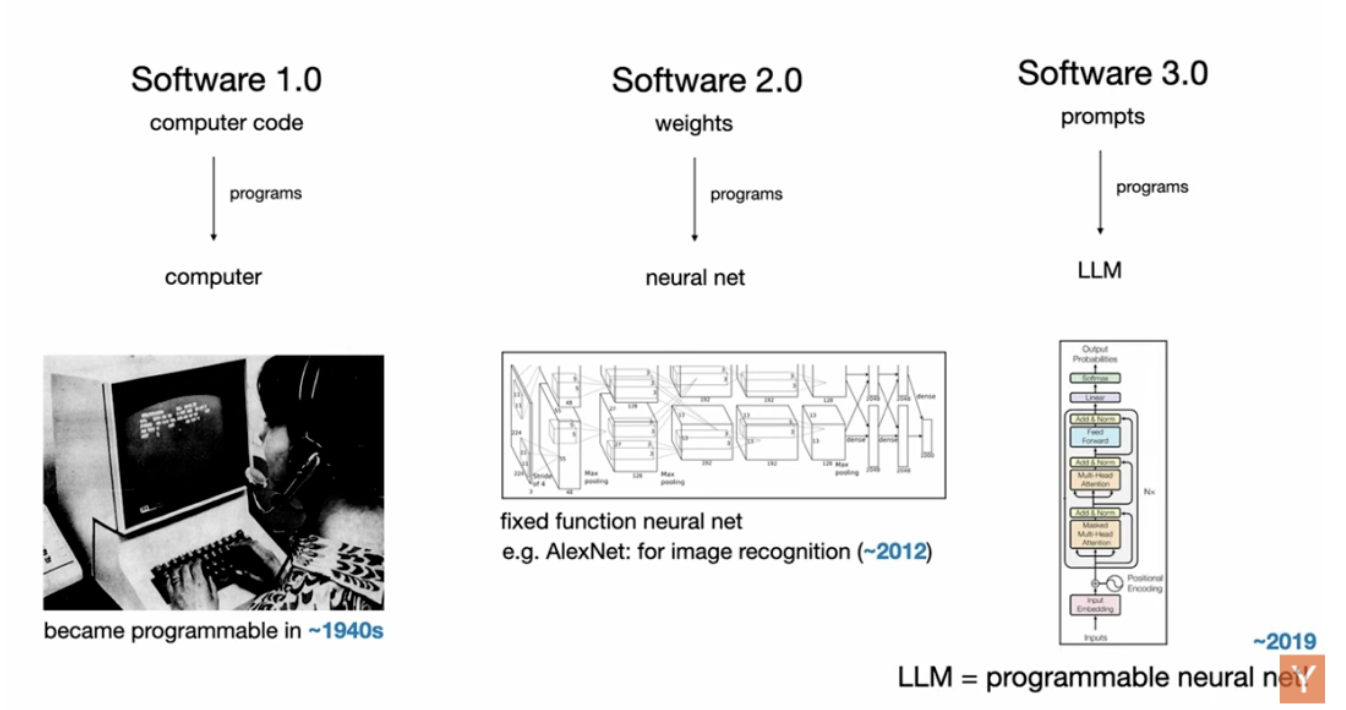
现在,你写的 prompt 就是“程序”,而它运行在大模型之上。更奇妙的是——这些“程序”居然是用英语写的!
这是一种非常特别的编程语言。
因此,现在我们已经拥有三种完全不同的编程范式:
Software 1.0:手写逻辑;
Software 2.0:训练参数;
Software 3.0:用 prompt 驱动大模型。
我建议任何即将入行的人,都要对这三种范式“多面手”,因为它们各有优劣:
有时你想显式写逻辑,那就用 1.0;
有时你想训练模型,那就用 2.0;
有时你只需要 prompt,那就用 3.0。
02
大模型(LLMs)不是“算法”而是“操作系统”
接下来,我想聊聊大语言模型(LLMs)所代表的新计算范式,以及这个新“计算生态”长什么样子。
我很早以前看到一句话让我印象深刻,是 Andrew Ng 说的:
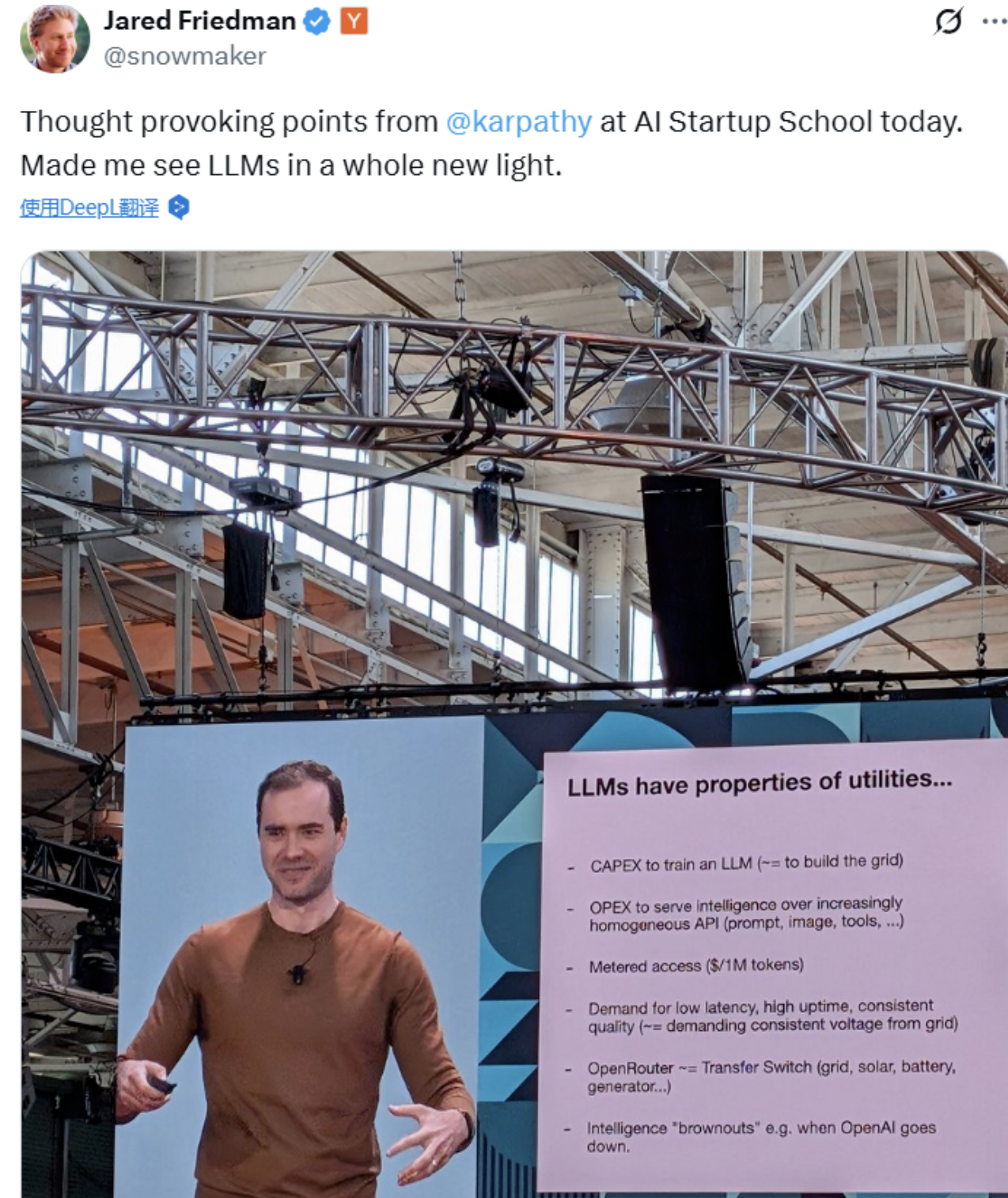
“AI 就像是新时代的电力。”
这句话点出了关键点:
LLM 实验室(如 OpenAI、Gemini、Mistral 等)投入资本(CapEx)来训练模型;
然后用运营开销(OpEx)通过 API 向开发者“输送智能”;
模型按 token 计价,像电力一样被“计量使用”;
我们对这些模型的要求也非常像“基础设施”:低延迟、高可用、稳定输出。

假设你切换电源时需要一个转换开关(transfer switch),我们在用 LLM 时也需要在不同模型之间切换,比如通过 router 连接 Claude、GPT、Gemini。
“当 SOTA 模型宕机的时候,简直就像是全世界都‘断电’了。就像电压不稳,全球都在‘降频’运行。”
但和电不一样,LLM 不是一种简单商品,而是一个复杂的软件系统,甚至更像操作系统(Operating System):
OpenAI、Anthropic 就像是 Windows 和 macOS;
而开源模型(如 Mistral、Qwen、LLaMA)则更像 Linux;
操作系统的作用不是“运行某个功能”,而是构建一个“平台”来承载更多功能;
同样地,LLM 并不是自己在“完成任务”,而是承载了很多提示词、工具、代理(agents)等“运行时系统”。
当然,现在的 LLM 还处在非常早期的阶段,它们本质上还是“语言模型”。
但现在的趋势非常清晰:重点不再只是模型本身,而是围绕它的工具链、模态集成、交互协议等全面生态。
我当初意识到这一点时,尝试画了一张草图:
LLM 是一种新型“计算机”,类似于 CPU;
Context window(上下文窗口)就是内存;
LLM 负责协调“内存 + 计算资源”来解决问题;
它使用的“能力插件”正在不断扩展。
从这个角度看,LLM 看起来非常像一个新型的“操作系统”。
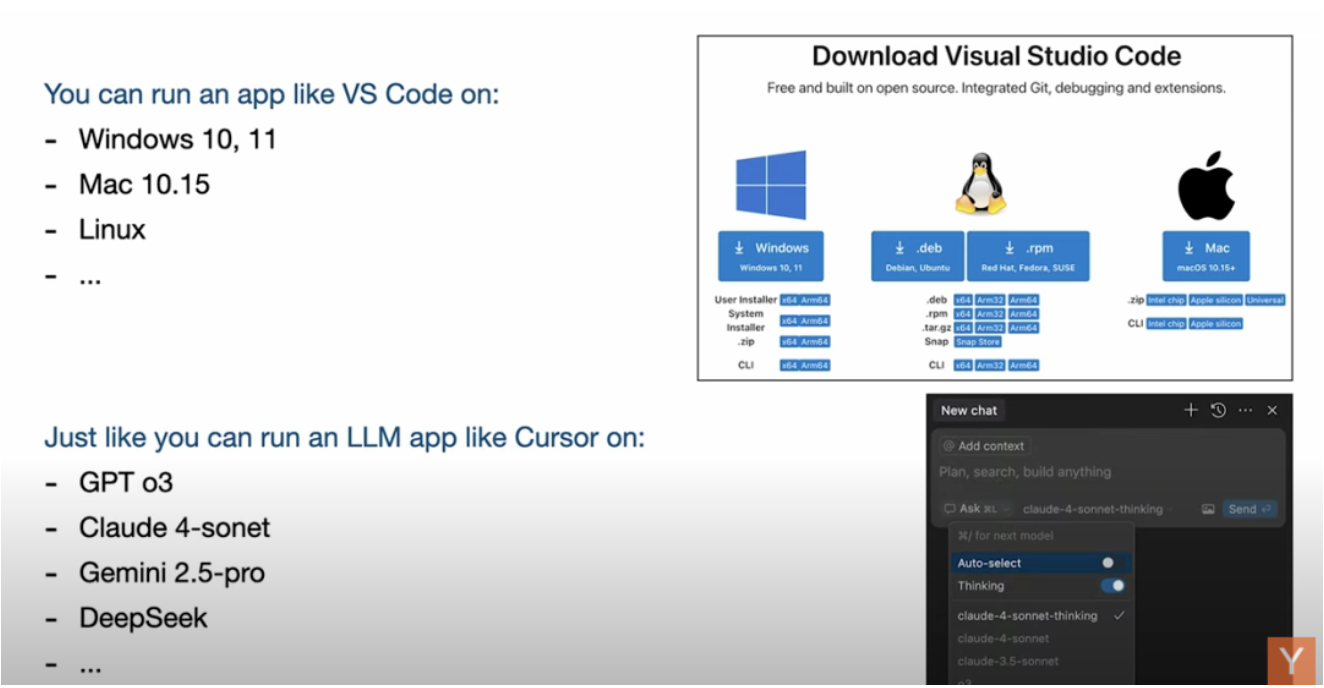
还有个类比我很喜欢:
比如你要下载一个 App,比如 VS Code。你可以在 Windows、Linux、macOS 上运行。
同理,你也可以拿一个基于 LLM 的 App,比如 Cursor,部署在 GPT、Claude、Gemini 上。
这些模型像是不同系统平台,而 App 则是通用的可插模块。
03
我们还没进入“AI 个人计算机时代”
我们现在的 LLM 计算,处于类似“1960 年代”的阶段。
LLM 推理成本仍然很高;
所以模型计算被集中部署在云端;
而我们就像瘦客户端(thin client),通过网络远程访问;
没有人真正“独享”一台模型计算机。
于是我们回到了“分时共享制”(Time-Sharing)的计算模式——大家排队用一台模型,在云里“批处理”执行任务。
“现在像是在 1960 年代,大家排队使用计算资源。未来是否能像 1980 年代那样迎来个人化 AI?我们还不知道。”
当然,也有一些尝试正在发生:
比如 Mac Mini 被证明是一些 LLM 的理想平台;
如果你的使用方式是“批量推理 + 高内存消耗”,那么本地推理其实是可行的。
这些是个人化 AI 的早期迹象,但还远远谈不上普及。
也许在座的某位会定义下一代个人 AI 计算机的模样。
04
与 LLM 交互像是用“命令行”,而 GUI 还没诞生
每次我和 ChatGPT 聊天,就像是在“命令行终端”中和操作系统对话。
目前我们还没有一个真正意义上的 GUI(图形用户界面):
ChatGPT 只是一个对话气泡;
你能用它做事,但它并不适合所有任务;
很多未来的 LLM 应用需要建立自己的 GUI;
目前没有一个通用的、跨任务 GUI 接口存在。

05
AI的技术扩散路线“上下颠倒”,这项革命性技术属于所有人
大语言模型(LLM)和操作系统虽然有很多相似之处,但它们也有一些非常独特的不同点,尤其是在技术扩散路径方面。
比如说,电力、密码学、计算机、飞行、互联网、GPS 等等——这些具有变革性的技术,过去都是从政府和大公司先用起来的。
因为它们昂贵、门槛高,只有大型机构能率先试水,之后才逐渐扩散到消费者手中。
但 LLM 完全反过来了。
大众用户才是最早的 adopter,而政府和大企业反而是后知后觉的那批。
所以这次技术扩散是“上下颠倒”的。这项革命性技术不再掌握在政府或大公司手里,而是属于我们所有人——因为它只是软件,我们每个人都可以用!
ChatGPT 就像“被光速投射到了我们每一台设备上”,转眼之间,几十亿人拥有了这台新计算机。
06
LLM 是“有缺陷的灵魂”:幻觉、近事遗忘、安全性
LLM 拥有百科全书式的知识和记忆力,远远超过任何单个人类。
当然,它们也有很多认知缺陷:
它们常常幻觉(hallucinate),会“编造”内容;
它们缺乏真正的自我认知模型;
虽然这些问题已经有所改善,但还远未解决;
它们展现的是“锯齿状智能”——某些方面超人类,某些方面蠢到爆。
比如,模型可能坚称:9.11 > 9.9,或者“strawberry”里有两个 r,这些就是经典的例子。
所以它们仍然有很多“坑”,你可能一不小心就踩进去。
另一个非常独特的问题是——近事记忆缺失(anterograde amnesia)。
你可以把 LLM 想象成一个刚入职的新同事:随着时间推移,它应该越来越了解公司流程、吸收上下文,并建立自己的专业知识结构。但LLM没有真实的成长,它们的记忆完全依赖你提供的上下文窗口(context window)。
换句话说:
它们不会自己变聪明;
你必须“显式编程”它的工作记忆;
很多人对这点理解不足,被“AI 能自学”的幻觉误导。
我建议大家看两部电影:《记忆碎片》(Memento)和《初恋50次》(50 First Dates)。
两部片子里的主角都患有记忆缺陷——每天早上醒来都失去前一天的记忆。
你想想,在这种状态下去工作、去建立关系,真的太难了。

还有一个值得注意的问题是安全性。
LLM 非常容易被欺骗,比如 prompt injection 攻击;也有可能泄露数据。
我们面对的是一种拥有超能力但又有严重缺陷的数字生命体。
我们要思考的是:
如何编程这些 LLM?
如何绕过它们的缺陷?
如何发挥它们的“超人力”?
07
部分自治软件:下一代 LLM 应用的基本形态
我们该如何使用这些模型?又有哪些令人兴奋的机会?
第一个我感到特别兴奋的方向是:部分自治应用(Partial Autonomy Apps)。
为什么你要复制粘贴代码到 ChatGPT,再复制粘贴回来,而不是直接在一个“懂代码”的 IDE 中完成?
因此比起ChatGPT,我更推荐你使用Cursor。
Cursor 是一款早期的 LLM 应用典范,它具备一系列通用特征,值得所有 LLM App 借鉴:
一方面,它保留了传统 IDE 界面,允许用户手动操作;
另一方面,它也集成了 LLM,可以处理更大规模的修改、生成任务;
用户可以按需调用 LLM 处理不同粒度的任务。
还一个关键特性是我称之为“自治滑块(Autonomy Slider)”:你始终掌控着自治滑块,根据任务复杂度来决定给 LLM 多大的权力。
还是以 Cursor 为例:
你可以选择自动补全(最小自治);
也可以选中一段代码按 Command+K,让它只修改这一段;
或者按 Command+L,修改整个文件;
甚至按 Command+I,让它对整个 repo“放飞自我”,自由重构(最大自治)。
总结来说,LLM 应用的关键特征是:
人类可以完整手动操作:传统输入仍可用;
LLM 做上下文管理与调用编排:后台 orchestrate 多模型;
有 GUI 可审查生成内容:例如高亮 diff、快捷接受/拒绝;
自治程度可调:从部分生成,到一整页改写,用户自主选择。
08
我们和LLM进入协作阶段
我们和 LLM 之间的关系,已经变成了协作。
AI 负责生成(generation);
人类负责验证(verification)。
我们的目标应该是:让生成-验证这个闭环尽可能快地运行起来,这样我们才能真正提效。
要加快这个循环,我认为有两个关键点:
1.加快验证流程
GUI 是实现这一点的重要工具。
阅读纯文本很费劲,而看图形是高效的。图像是一条“通向大脑的高速公路”。
所以,从系统审查效率来说,图形化呈现非常重要。
2.我们必须给 AI 套上缰绳(on a leash)
现在很多人对 AI Agent 的能力过于乐观。
但问题在于:
“我不想一次性收到一个 1000 行代码 diff。”
即便这些代码一瞬间生成,我作为人类审查者依旧是整个流程的瓶颈。
所以我的个人习惯是:
绝不一次生成太大 diff;
始终采取“逐块小修改”的方式;
每一步都快速验证,然后再往下推进。

我相信我们很多人都在逐步摸索出适合自己的方法论。
09
软件真的很难,不要去做炫技的“全自治 Agent Demo”
我想顺便分享一个故事:
我第一次坐上自动驾驶汽车是在 2013 年。
我当时的感觉是:天啊,自动驾驶已经实现了,它真的能跑了。
结果现在都 12 年过去了,我们还在努力攻克自动驾驶的问题。
Waymo 的车现在看起来“无驾驶员”,但其实仍然有很多远程操作、很多人类介入。
我想说的是:软件真的很难。
它的难度和自动驾驶几乎是一个等级。
所以当我看到有人说“2025 是智能体(agents)元年”,我会感到警惕。
我想说的是:这是“Agent 的十年”,不是某一年的事情。
我还特别喜欢用《钢铁侠》作为比喻。
我一直都喜欢这个角色,它以很多方式非常贴切地反映了技术的演进。
你看,钢铁侠战衣既是一种增强工具(augmentation),也具备自主智能体(agent)的特征:
有时候托尼·斯塔克亲自驾驶它;
有时候它能独立飞行、自动寻找目标,还能“找回主人”;
这就是“自治滑块”的不同模式。
现在这个阶段,我认为:
与其说我们在构建“Iron Man 机器人”;
不如说我们更像是在打造“Iron Man 战衣”。
我们真正要做的,不是去做炫技的“全自治 Agent Demo”,而是做那些具有部分自治、真正实用的产品。
这些产品:
拥有定制化的 GUI 和交互体验;
能让生成-验证的闭环极快运转;
又不失控、可监督;
同时也保留了未来可以逐步自动化的可能性。
你应该思考:你的产品中是否已经有“自治滑块”?你能不能逐步推动它向更高自治程度演进?
在我看来,这类“增强人 + 可调节 Agent”的混合产品,才是当前最具潜力的方向。
10
“Vibe Coding”走红:我们应该“走向中间”,与 LLM 会合
不知道你们有没有听说过“Vibe Coding”?
我发的这条推文,就是在讲这个概念——后来它变成了一个爆火 meme:
“英语不是编程语言,但它现在就是了。”
这条推文当时我以为不会有人在意,就像很多“灵感一闪”的碎碎念那样。
结果,它意外走红,大家疯狂转发。
因为它刚好说出了很多人心里的感受:我们都感觉到事情变了,却一时找不到一个词来定义。
现在甚至有了对应的 Wikipedia 页面(笑),这算是我为时代贡献的一个新术语吧。
我也试着搞了点「vibe coding」,因为它真的很有趣,其中包括一个叫 MenuGem应用,拍菜单自动生成图片展示,大家现在就能去试:menugem.app。
vibe coding的感受是:
编码本身(vibe coding)很简单;
反而最麻烦的,是接入登录、支付、部署等 DevOps 环节;
比如谷歌登录,网页写了一大堆“点击这→跳到那→点确认”,都是给人操作的,而不是设计给 Agent 调用的。
所以: “我们以前只为人类构建 GUI,现在要为 LLM 构建 API 生态。”
我的观点是:
对于绝大多数产品来说,我们应该“走向中间”,与 LLM 会合;
与其等 LLM 完美,不如我们主动调整格式、协议、接口。
最后总结
总结一下:
现在是进入这个行业的黄金时刻。
我们要重写大量代码,而这部分会由专业人士、也会由“vibe coder”来完成。
LLM 像是公用设施(utilities),像是 AI 晶圆厂(fabs),但更像是操作系统。
而这一切,才刚刚开始——这还是“操作系统的 1960 年代”。
这些模型本质上就像数字人格,有缺陷,但极强大,我们要学会与它们共处。
为此,我们需要重塑软件基础设施。
未来十年,我们会不断把“自治滑块”从左往右推进。
这个过程会非常有趣,我也等不及要跟大家一起去创造它了。
评论